Recap
In the last post, we imported the data provided from Quora. It was split 9:1 into training and test data (unlabled with __ans__ missing). But we will also need to split our data even further. I am talking about using part of the labeled training data to check the accuracy of our model.
In this post, I will do regression models and evaluate their accuracy. I am new to regression; as a result, this post won’t be focused on the Quora challenge, rather, it is an exposition to help me better understand regression models.
Let’s start by importing the data:
import pandas as pd
import json
json_data = open('../views/sample/input00.in') # change to where your `input00.in` file is
data = []
for line in json_data:
data.append(json.loads(line))
data.remove(9000)
data.remove(1000)
df = pd.DataFrame(data)
data_df = df[:9000]
data_df
| __ans__ | anonymous | context_topic | num_answers | promoted_to | question_key | question_text | topics | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2.089474 | False | {'followers': 500022, 'name': 'Movies'} | 4 | 0 | AAEAAM9EY6LIJsEFvYiwKLfCe7d+hkbsXJ5qM7aSwTqemERp | What are some movies with mind boggling twists... | [{'followers': 500022, 'name': 'Movies'}] |
| 1 | 2.692308 | False | {'followers': 179, 'name': 'International Math... | 1 | 0 | AAEAAHM6f92B9jt43/y913/J7ce8vtE6Jn9LLcy3yK2RHFGD | How do you prepare a 10 year old for Internati... | [{'followers': 179, 'name': 'International Mat... |
| 2 | 4.612903 | False | {'followers': 614223, 'name': 'Science'} | 1 | 0 | AAEAAGzietPvCHLFvaKCjng43iiIeo9gAWnJlSrs+12uYtZ0 | Why do bats sleep upside down? | [{'followers': 614223, 'name': 'Science'}] |
| 3 | 8.051948 | False | {'followers': 614223, 'name': 'Science'} | 1 | 0 | AAEAAM2Sk4U3y4We5TELJXRQgIf6yit5DbbdBw6BCRvuFrcY | Tell me everything about the Leidenfrost effec... | [{'followers': 614223, 'name': 'Science'}, {'f... |
| 4 | 0.150943 | False | {'followers': 1536, 'name': 'Android Tablets'} | 0 | 0 | AAEAALb43r/fn9KRKqJ0itd3NGbqZZSZalzi7vaulLxNGzeL | Is the Nexus 10 any good despite the dual core... | [{'followers': 1536, 'name': 'Android Tablets'}] |
| 5 | 0.084507 | False | {'followers': 91, 'name': 'Smartphone Applicat... | 0 | 0 | AAEAABSJk8mrfAjuQuxEI6PV2rfGGcnuq/I5JyE0VJvYSoRp | Is smartphone app download duplication account... | [{'followers': 91, 'name': 'Smartphone Applica... |
| 6 | 1.073944 | True | {'followers': 241809, 'name': 'Startups'} | 1 | 200 | AAEAANLGb0hKlFULx6BPXvVvHQ1SJ2jJTqDCVighUGs/ZDya | Are there any CEO's that go by a different nam... | [{'followers': 526597, 'name': 'Business'}, {'... |
| 7 | 0.007299 | False | None | 0 | 0 | AAEAAJinkGKp/YRlvWhFbapFNzPkD7coBuf4QRwsmN/c3q7Z | Guys who love being sissies? | [{'followers': 289, 'name': 'Needs to Be Clear... |
| 8 | 0.298893 | True | {'followers': 3006, 'name': 'Warfare'} | 1 | 0 | AAEAAB0zSrCTxmdSYxoC1KD0HYeDwTzOyK2lBiXzuZwhhmgn | How does one successfully become a conscientio... | [{'followers': 59, 'name': 'Pacifism'}, {'foll... |
| 9 | 30.614035 | False | {'followers': 224, 'name': 'Boston Marathon Te... | 3 | 0 | AAEAAA7uRr9KzVD3rd+L3OptfwxaWFYfE6D8Wqskxx+ZkfGb | How do people in countries with regular and la... | [{'followers': 224, 'name': 'Boston Marathon T... |
| 10 | 24.250000 | False | {'followers': 4155, 'name': 'Organization'} | 0 | 0 | AAEAAFHJ+5Ozj1TQKLUwzB/pIwiXMwtTJip8NQO1jCCyRS5a | How do top entrepreneurs/CEOs stay organized a... | [{'followers': 321001, 'name': 'Entrepreneursh... |
| 11 | 1.666667 | False | {'followers': 304, 'name': 'Web Development on... | 0 | 0 | AAEAAM3WIWO/Ct/u5SvzPHfwwrHNWrPgHd8Ch7/QdM6CjfZL | What companies/independent developers located ... | [{'followers': 199, 'name': 'Technology Indust... |
| 12 | 0.006231 | False | {'followers': 3292, 'name': 'United States Gov... | 0 | 0 | AAEAAI0XKapeO3+B75zZYu1Kjv5SGn+Mm/4qT3rBNJrDNKce | How can I call and talk with President Obama o... | [{'followers': 1240, 'name': 'U.S. Presidents'}] |
| 13 | 0.575972 | True | {'followers': 13867, 'name': 'Parenting'} | 1 | 100 | AAEAAMRnMKIzVIfH55p+aKXak1M0vBd2m7xNKm5KttYyVspo | What do parents wish they had known before hav... | [{'followers': 26, 'name': 'Deciding Whether t... |
| 14 | 5.220859 | False | {'followers': 72820, 'name': 'Biology'} | 2 | 0 | AAEAAFsd5v511xAQgtEaPDHb+fYF8YSJnsRuMd7715LVQQPf | How much time does it take to go from DNA to p... | [{'followers': 3693, 'name': 'Medical Research... |
| 15 | 0.079755 | False | {'followers': 2049, 'name': 'Tablet Devices an... | 0 | 0 | AAEAAOnLQc1KPDw0pqCMpROkdovdRCzJlTsI5nDo9vxjcOm+ | What % of tablet users use a stylus? | [{'followers': 2049, 'name': 'Tablet Devices a... |
| 16 | 1.075758 | False | {'followers': 999, 'name': 'Luxury'} | 0 | 0 | AAEAAI0A/7ASkze8LKdTLRwCFtUcFZ2xIpNnS55Zk1xtCwXN | Which company make awesome luxury coach? | [{'followers': 999, 'name': 'Luxury'}, {'follo... |
| 17 | 0.717557 | False | {'followers': 39744, 'name': 'Web Development'} | 1 | 0 | AAEAAKKuKEgb+lBKi1iEEST89zLKFr/88CUAwC9xeCdGYss1 | I Require professional and creative web desig... | [{'followers': 39744, 'name': 'Web Development'}] |
| 18 | 1.622010 | False | {'followers': 3566, 'name': 'Online Video'} | 2 | 0 | AAEAAJloaH19a32hbe1Cs0wdW8WWptHbbaa5JG7dKbMwvtaJ | What are the short/medium prospects of service... | [{'followers': 11842, 'name': 'Internet Advert... |
| 19 | 3.388889 | False | {'followers': 268430, 'name': 'Television Seri... | 0 | 0 | AAEAAFHbVuHDWmLslFWH8UZMnN7M5VHntFVDpY19+3ndhmy5 | Why can't we create something like game of thr... | [{'followers': 268430, 'name': 'Television Ser... |
| 20 | 11.457143 | False | {'followers': 74, 'name': 'Noodle Education'} | 0 | 0 | AAEAAKkkEpxZp4qBn45yEhzGTnJNhB5e/Mppn75kx1on5ajr | Would Noodle make other education lead generat... | [{'followers': 167176, 'name': 'Business Model... |
| 21 | 1.013889 | False | {'followers': 490, 'name': 'Online Reputation'} | 1 | 0 | AAEAABu6kZw48xJyS1xXW3RjQ0xANWgzwjp6LLVTryDWUM8I | ORM is all too often seen simply as minimising... | [{'followers': 490, 'name': 'Online Reputation... |
| 22 | 0.389474 | True | {'followers': 264984, 'name': 'Dating and Rela... | 1 | 0 | AAEAANJFMVE7CEr6gX3LEC9NWGz0a65TjFd1AjHMY9CWujBJ | What are some of the funniest noises you have ... | [{'followers': 67265, 'name': 'Sex'}, {'follow... |
| 23 | 0.319231 | False | {'followers': 6608, 'name': 'Science and Relig... | 1 | 0 | AAEAAKTTk5EUSD+0CPGP0gLS0aBQR97xe0p2+DPRX+ddtoV2 | Was Moses talking about humans becoming fully ... | [{'followers': 2525, 'name': 'Theology'}, {'fo... |
| 24 | 4.000000 | False | {'followers': 1707, 'name': 'Democracy'} | 4 | 200 | AAEAAFJxWj/4n1NhOgwpS0d5X7tcBia4jBtjrfw6YxNcYXDr | 'Scarcely a human freedom has been obtained wi... | [{'followers': 4332, 'name': 'Occupy Movement'... |
| 25 | 0.174194 | False | {'followers': 2450, 'name': 'Wanting and Makin... | 0 | 0 | AAEAAH+k9PIQg6lOxHRIqXYE5u18aWO4QqJZTtdahJw9+grv | Do actors get paid after they do the movie or ... | [{'followers': 2450, 'name': 'Wanting and Maki... |
| 26 | 0.678322 | True | {'followers': 3567, 'name': 'Private Equity'} | 0 | 0 | AAEAAG1dK7AL02j78ugkPaKf5TiFb6iBCaIICXxUd5OYpQYz | Private Equity in relation to Movie Industry,c... | [{'followers': 3567, 'name': 'Private Equity'}... |
| 27 | 1.007246 | False | {'followers': 238905, 'name': 'Facebook'} | 2 | 120 | AAEAAA15xfSTbyLayedu+P4P6upyw1gZisruGcd5sBeOiO2w | What language was used by Mark Zuckerberg to w... | [{'followers': 238905, 'name': 'Facebook'}] |
| 28 | 46.333333 | False | {'followers': 238905, 'name': 'Facebook'} | 0 | 0 | AAEAALJZ+JSLst8wPq+EApQqSTqcCW9iaHg7OWcdwg+xJEVo | How employees at Facebook avoid procrastinatio... | [{'followers': 238905, 'name': 'Facebook'}] |
| 29 | 0.615385 | True | {'followers': 986, 'name': 'Glenn Gould'} | 0 | 0 | AAEAAETPeE1zK+aIF5IeOLu2EzMwzSM22EM4i14ZnwDTU17t | Was Glenn Gould a fast typist? | [{'followers': 986, 'name': 'Glenn Gould'}] |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 8970 | 0.044610 | False | {'followers': 3899, 'name': 'Quora (company)'} | 0 | 0 | AAEAAKy7JJbuCln18hVXHhNCqaW/2t4BOJekq4EoJZeZlQAf | When was the Quora application launched for An... | [{'followers': 3899, 'name': 'Quora (company)'}] |
| 8971 | 0.028571 | False | {'followers': 53, 'name': 'The Flame'} | 0 | 0 | AAEAAIPL+PIfMKP6q/d3vCLPeN6qaE5wVTv9jyLyP46riITO | 1A group element to show flame test why? | [{'followers': 13, 'name': 'Flame Effects'}, {... |
| 8972 | 0.356364 | False | {'followers': 39744, 'name': 'Web Development'} | 0 | 0 | AAEAAFbZen2AwK+cWhTuxYq89OYYGUdvPKxObTA49ZZY5EoF | Hire best webdevelopers to design and maintain... | [{'followers': 39744, 'name': 'Web Development'}] |
| 8973 | 101.000000 | True | {'followers': 264984, 'name': 'Dating and Rela... | 1 | 0 | AAEAAEKenPCvJnNPSn3GoyxJGHOgO9Ft1sXtcQIRtzX36ls7 | Is it absolutely necessary to have a lot in co... | [{'followers': 264984, 'name': 'Dating and Rel... |
| 8974 | 0.424658 | False | {'followers': 0, 'name': 'Numeration'} | 0 | 0 | AAEAAJ6h5w42SdKWHM1ba0mDrLXfRNF35x5J1ImAXc5k7r9g | What civilization had the earliest written num... | [{'followers': 1460, 'name': 'Numbers'}, {'fol... |
| 8975 | 1.787879 | True | {'followers': 7928, 'name': 'Recruiting'} | 2 | 0 | AAEAAI0sA6MSlU+uVCoRL9a3wpk5dt0Mnwy/8h0l2jkqoE9K | I am never contacted by recruiters (I don't ha... | [{'followers': 7928, 'name': 'Recruiting'}] |
| 8976 | 0.183673 | False | {'followers': 4729, 'name': 'Software'} | 0 | 0 | AAEAAHQncZgikc5wl/qwturXJ89iVLVLNrUJNGpMfiSGkZLK | What is finance software? | [{'followers': 4729, 'name': 'Software'}] |
| 8977 | 0.118902 | True | {'followers': 93447, 'name': 'Amazon'} | 1 | 0 | AAEAAIo1t0EvlXTB3vDMjt4DCsJeG6U43ZF/aD8SiMmlmof0 | What impact do foreign currency fluctuations h... | [{'followers': 93447, 'name': 'Amazon'}] |
| 8978 | 0.494382 | True | {'followers': 4859, 'name': 'Sales'} | 1 | 0 | AAEAACkrgngYk0Gq2+2Jm/c+yfNG3tFyUrZAUpEsbvfAnuAo | What are some tips to write a great sales copy? | [{'followers': 4859, 'name': 'Sales'}, {'follo... |
| 8979 | 2.323699 | True | {'followers': 13108, 'name': 'Career Advice'} | 1 | 0 | AAEAAKF/1Zvtgov2mB0Ji4jg1/0aE+lQkKxIEhQuLX8yuwzY | Is it a good idea to use technical jargon when... | [{'followers': 13108, 'name': 'Career Advice'}] |
| 8980 | 0.044944 | True | {'followers': 3, 'name': 'Done Genetics'} | 1 | 0 | AAEAAN2Q0FsMgTWonNul3FPog92E1XkMDr+1QcPsIivJyv/z | What's it like to work at Done Genetics? | [{'followers': 3, 'name': 'Done Genetics'}] |
| 8981 | 2.752941 | True | {'followers': 20107, 'name': 'Mumbai, Maharash... | 3 | 0 | AAEAAPJKiEWYD6YX59MhOtX8+DnzOqzul+SpdL2Xnl0KJoxx | Where can I connect with people in general in ... | [{'followers': 6467, 'name': 'Colleges and Uni... |
| 8982 | 0.011662 | True | {'followers': 3168, 'name': 'Dublin, Ireland'} | 0 | 0 | AAEAAOZFkLJxzpcxaMgr6sM3pBQcOKWQq+ykds/w3GXXgZqo | Have anyone any concern or recommendation for ... | [{'followers': 289, 'name': 'Needs to Be Clear... |
| 8983 | 0.133929 | False | {'followers': 238905, 'name': 'Facebook'} | 0 | 0 | AAEAAFxvsqu2YCjgWfq2u+anT+J0OXvtANXSu+elB7CuM1G2 | How can I tell facebook to stop emailing me? | [{'followers': 238905, 'name': 'Facebook'}] |
| 8984 | 0.207373 | True | {'followers': 809, 'name': 'Auto Insurance'} | 1 | 0 | AAEAAHaEN4jlW0hrNd+wj1Xx9bWV2XiE0+5kkBbpk0cS/XCD | Who does cover hound use to provide auto rate ... | [{'followers': 809, 'name': 'Auto Insurance'}] |
| 8985 | 0.662722 | True | None | 2 | 0 | AAEAAO10zYF1GIDQenYcsr4KV8T5f53wX0d491daxFrxJfxE | Is Wuthering Heights a feminist text? | [{'followers': 590279, 'name': 'Books'}, {'fol... |
| 8986 | 4.123288 | False | {'followers': 500022, 'name': 'Movies'} | 1 | 200 | AAEAAIO1CRxV7oxl//ejIL5mkNUJqShjAlSNiOaXEiQFChq+ | How will better audience data change the movie... | [{'followers': 1, 'name': 'User Data'}, {'foll... |
| 8987 | 0.352941 | False | {'followers': 361, 'name': 'Royalty'} | 0 | 0 | AAEAAOKeIMX2TbFS2CdHXtBWs++0egdI5p4FB2TZTlLyph7D | In what condition to descendants of royalty live? | [{'followers': 361, 'name': 'Royalty'}] |
| 8988 | 0.488525 | False | {'followers': 24985, 'name': 'Innovation'} | 0 | 400 | AAEAALlzDzfzi6ULFlDFEbxjfkQTdJRmyDeB7Oz343GX3Zzz | Will the developing world be more innovative d... | [{'followers': 24985, 'name': 'Innovation'}, {... |
| 8989 | 6.908078 | False | {'followers': 782, 'name': 'Samurai'} | 5 | 0 | AAEAAJj02/B0zzfVYoV/ujoCNopCXWyQ1l1joancxgjHTOvc | Are there living samurai in this age? | [{'followers': 12423, 'name': 'Japan'}, {'foll... |
| 8990 | 2.077295 | False | {'followers': 20706, 'name': 'Self-Improvement'} | 1 | 200 | AAEAAF3/vH5TKSTV79CQ2wWCe7UPuPUQ7GqKZ+zy/WZpyWTS | How is it like to hire a life coach or persona... | [{'followers': 11233, 'name': 'Life Advice'}, ... |
| 8991 | 0.490798 | False | {'followers': 13867, 'name': 'Web Applications'} | 2 | 400 | AAEAABeFQkBTvekTH2LwM9QRMeaYrb43rq4KQTB3ixkjIUW6 | What happens to my links if I disconnect my cu... | [{'followers': 1483, 'name': 'Bitly'}, {'follo... |
| 8992 | 0.197080 | False | {'followers': 295, 'name': 'Curiosity (Mars Ro... | 2 | 0 | AAEAAG1ehKZlxWfZ3u8Ty8xu5l2N+kghEcv62oITGGiqZj62 | Can Curiosity record sound? | [{'followers': 295, 'name': 'Curiosity (Mars R... |
| 8993 | 3.375000 | False | {'followers': 6423, 'name': 'Germany'} | 1 | 0 | AAEAAITna52dCVn2KCVY3+xhMh4dbliiirA/gdi74f+v2zyG | Is it realistic to think you can get a decent ... | [{'followers': 6423, 'name': 'Germany'}] |
| 8994 | 0.482143 | False | {'followers': 0, 'name': 'Syrian War'} | 1 | 0 | AAEAAB8MgrMHBPrcEd+z8uWtFtE0jU1VhHBx4bSj3dLaMait | Can someone explain to me how the Syrian war b... | [{'followers': 854, 'name': 'Syria'}, {'follow... |
| 8995 | 2.850000 | False | {'followers': 10123, 'name': 'Animals'} | 0 | 0 | AAEAANESwEBxHZJt2IIhT1/YgqvPOOHySqU0TPMHvefVX6Rn | How old are the wolves growly pants and truck ... | [{'followers': 10123, 'name': 'Animals'}, {'fo... |
| 8996 | 0.274648 | False | {'followers': 7149, 'name': 'iPad Applications'} | 0 | 0 | AAEAABT6OZZisoRkeAFNxYWAssLUu45g4iNjeQiaAEVkPa2Z | What is the best Agenda (notes, gant charts, C... | [{'followers': 7149, 'name': 'iPad Application... |
| 8997 | 3.146893 | True | {'followers': 146, 'name': 'The Hobbit (movie ... | 1 | 0 | AAEAAAUdDfIgSIYlFRrY4jOKvHsvSLmlKjyZ576oP8a+L694 | December 2012: Are all the Hobbit films alread... | [{'followers': 18741, 'name': 'The Hobbit (193... |
| 8998 | 0.131086 | False | {'followers': 7260, 'name': 'Real Estate'} | 0 | 0 | AAEAADeVLG2awg6hG+dTiPKRiII64khN7fS/OeFLek4lg2QQ | Rental Navigator asks...If you are a real esta... | [{'followers': 7260, 'name': 'Real Estate'}] |
| 8999 | 2.738739 | False | {'followers': 199773, 'name': 'Physics'} | 2 | 0 | AAEAAKeoz9V34X6kt6Iq+ywD6JKTBkJxointHniuxnF2ejHa | Energy of motion turns into mass? | [{'followers': 199773, 'name': 'Physics'}] |
9000 rows × 8 columns
Preparation
We will not deal with columns with text (in the next posts, we will explore these features). That is, question_text will be dropped. Moreover, as context_topic is depreciated, this column has no use for now.
data_df.drop(['context_topic', 'question_text'], axis=1, inplace=True)
The topics column has JSON object blobs. The total number of followers of the topics the question shows up under is a meaningful feature. Add it to the data frame as follows:
# JSON blob cleanup for topics column
def funn(x): #where x will be a row when running `apply`
return sum(x[i]['followers'] for i in range(len(x)))
data_df['topics_followers'] = data_df['topics'].apply(funn)
data_df.drop(['topics'], axis =1, inplace=True)
The anonymous column has boolean values. Since the machine learning algorithms only take numerical values, the column needs to be relabeled.
# Turn the boolean valued 'anonymous' column to 0/1
data_df['anonymous'] = data_df['anonymous'].map({False: 0, True:1}).astype(int)
Finally, setquestion_key as the index and check that it’s unique.
data_df.set_index(data_df['question_key'],
inplace=True,
verify_integrity=True
)
data_df.drop(['question_key'], axis=1, inplace=True)
data_df.index.name = None
Since the new index has a name (“question_key”), pandas will add an extra row with this index name in the first entry and 0 in the rest. Fix this by setting the index name to None.
data_df.head()
| __ans__ | anonymous | num_answers | promoted_to | topics_followers | |
|---|---|---|---|---|---|
| AAEAAM9EY6LIJsEFvYiwKLfCe7d+hkbsXJ5qM7aSwTqemERp | 2.089474 | 0 | 4 | 0 | 500022 |
| AAEAAHM6f92B9jt43/y913/J7ce8vtE6Jn9LLcy3yK2RHFGD | 2.692308 | 0 | 1 | 0 | 179 |
| AAEAAGzietPvCHLFvaKCjng43iiIeo9gAWnJlSrs+12uYtZ0 | 4.612903 | 0 | 1 | 0 | 614223 |
| AAEAAM2Sk4U3y4We5TELJXRQgIf6yit5DbbdBw6BCRvuFrcY | 8.051948 | 0 | 1 | 0 | 1029363 |
| AAEAALb43r/fn9KRKqJ0itd3NGbqZZSZalzi7vaulLxNGzeL | 0.150943 | 0 | 0 | 0 | 1536 |
Preprocessing
Before choosing which preprocessing algorithm to use, the existence of outliers in our data must be checked. Normally, one would use MaxMinScaler or StandardScaler from sklearn.preprocessing. But in a data with outliers, a better option is RobustScaler. The rationale is discussed below.
Do we have outliers?
To gain a perspective, run:
data_df.describe()
| __ans__ | anonymous | num_answers | promoted_to | topics_followers | |
|---|---|---|---|---|---|
| count | 9000.000000 | 9000.000000 | 9000.000000 | 9000.000000 | 9.000000e+03 |
| mean | 7.753822 | 0.297556 | 1.849222 | 49.137778 | 1.757266e+05 |
| std | 37.803602 | 0.457208 | 5.837850 | 187.168118 | 2.634619e+05 |
| min | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000e+00 |
| 25% | 0.457780 | 0.000000 | 0.000000 | 0.000000 | 6.621000e+03 |
| 50% | 1.328110 | 0.000000 | 1.000000 | 0.000000 | 4.784200e+04 |
| 75% | 4.019578 | 1.000000 | 2.000000 | 0.000000 | 2.649840e+05 |
| max | 1569.000000 | 1.000000 | 311.000000 | 5600.000000 | 2.838840e+06 |
This hints that there are outliers in almost all of our features, except anonymous (and leaving out __ans__ as it’s often not required to scale the target). For more insight, let’s plot some boxplots.
# boxplots
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style("whitegrid")
plt.subplot(1, 3, 1)#i.e., this is the first (the last 1) in a 1 row plot of 2 columns.
plt.boxplot(data_df.num_answers, 1, 'gd')
plt.title('num_answers')
plt.ylabel('counts')
plt.subplot(1, 3, 2)
plt.boxplot(data_df.promoted_to, 1, 'gd')
plt.title('promoted_to')
plt.ylabel('counts')
plt.subplot(1, 3, 3)
plt.boxplot(data_df.topics_followers, 1, 'gd')
plt.title('topics_followers')
plt.ylabel('counts')
plt.tight_layout()
plt.show()
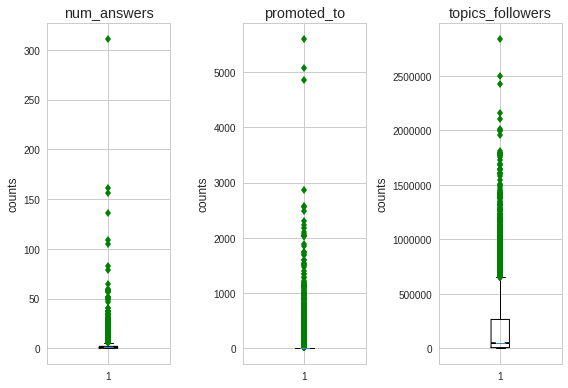
There are a few data points outside the IQR in each of the boxplots (in the first two, the boxes are the dark lines at the bottom). Certainly, these columns have outliers.
Because we have outliers, the sklearn RobustScaler will be used.
Standardization of a dataset is a common requirement for many machine learning estimators. Typically this is done by removing the mean and scaling to unit variance. However, outliers can often influence the sample mean / variance in a negative way. In such cases, the median and the interquartile range often give better results.
For a good measure, we will use a quartile range of (5.0, 95.0) which is 2 standard deviations (see three-sigma-rule).
Splitting
If preprocessing is done on the whole data before splitting the data to training and test sets, “information from the test set will ’leak’ into your training data.” (see this stats.SE answer.)
Now, not to confuse with the 9:1 split that was discussed in the previous post, this split is being done on the first 9000 data points. The other 1000, of the 10,000, are unlabled; so, we can only use the 9000 to train and check the validity of our models.
We will split data_df 8:2, train to test.
# Split data_df to train and test
from sklearn.model_selection import train_test_split
y = data_df.__ans__ # the target column
x = data_df.drop('__ans__', axis=1)
x_train, x_test, y_train, y_test = train_test_split(x, y,
test_size = 0.2,
random_state = 123)
pd.DataFrame(x_train).head()
| anonymous | num_answers | promoted_to | topics_followers | |
|---|---|---|---|---|
| AAEAALxMqeRHdD7LRQLR7RZfcSXRNvMoqdZQ1GAKFrFutwlU | 1 | 6 | 0 | 65367 |
| AAEAAAM93+e/vn8MQXZUdE4ECSfPVr/TY1wGwYU33sRFZOLU | 0 | 0 | 200 | 3210 |
| AAEAAHioJGo60T+xv1nrk+HnPJ68sHjUVAktaItioPwvRV1w | 1 | 0 | 0 | 24161 |
| AAEAAM9qePqcSQmZK+lRCFDMJ5Zx7l/MkW4smb8WROdeqZmK | 0 | 1 | 70 | 15157 |
| AAEAAI2b9z3fIB+4uTzBGGWEw3eDYIiH0ettb3kViJsI7RoA | 1 | 3 | 0 | 19195 |
Now prepare the scaler. By the way, since we are not composing estimators, we don’t need to use a pipeline.
# RobustScaler
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler(quantile_range=(5,95)).fit(x_train)
Then apply the scaler to both the train and test datasets, excluding the target feature; notice that the target feature is stored in dataframe y.
X_train = scaler.transform(x_train)
X_test = scaler.transform(x_test)
Regression
At this point, we are ready to use regression algorithms.
Decision Tree Regressor
Using the decision tree regressor, our model is created by predicting the value of the target feature by learning simple decision rules inferred from the data set we fit it on. In simpler terms, the model is created by performing a large scale pivoting.
First we will do it on our training set; that is, fitting the regressor with X_train and y_train:
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor()
tree_reg.fit(X_train, y_train)
Then make a prediction of the target feature from X_train.
y_pred_from_train = tree_reg.predict(X_train)
Finally, check the accuracy by calculating Root Mean Squared Error, that is, check how far off the predicted y is from the actual y_train.
from sklearn.metrics import mean_squared_error
import numpy as np
tree_mse = mean_squared_error(y_pred_from_train, y_train)
tree_rmse = np.sqrt(tree_mse)
tree_rmse
2.9395110047712159
This sounds too good to be true! Now, do this on the test dataset. Calculate rmse after predicting y using X_test. Recall that the regressor is trained on X_train and has not seen X_test. So, this is the real test of our model.
y_pred_from_test = tree_reg.predict(X_test) #make the prediction
tree_mse_test = mean_squared_error(y_pred_from_test, y_test) #calculate rmse
tree_rmse_test = np.sqrt(tree_mse_test)
tree_rmse_test
40.278871508455829
Okay, the error on the test set is 14 times that of the training set!! This doesn’t look good. But it’s not surprising as Decision Tree Regressor is prone to overfitting. So, it overfit the training set and thus performed badly on an unknown set, i.e., our test set.
Overfitting can be abated using sklearn’s Cross-Validation feature. I will demonstrate how we can perform K-fold cross-validation with K=10.
from sklearn.model_selection import cross_val_score
tree_scores = cross_val_score(tree_reg, X_train, y_train,
scoring = "neg_mean_squared_error", cv=10
)
tree_rmse_scores = np.sqrt(-tree_scores)
# taken from Aurelien Geron's Hands on ML book
def display_scores(scores):
print("scores: ", scores)
print("mean:", scores.mean())
print("standard deviation:", scores.std())
display_scores(tree_rmse_scores)
scores: [ 29.75540989 56.09513377 44.12899068 73.75383811 39.68194397
38.37672842 53.38223776 61.47702739 47.48127876 37.58361917]
mean: 48.1716207909
standard deviation: 12.4800354025
Linear Regressor
A linear regression model works by computing the target feature (__ans__ here) as a weighted sum of the predictor features (columns of X) plus an intercept term (which the model determines looking at the relationship between the predictors and the target features). Decision Tree, on the other hand, finds complex non-linear relationships in our data that the linear regressor misses.
Now let’s see how well the Linear Regression model does.
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X_train, y_train)
y_pred_train_lin = lin_reg.predict(X_train)
lin_rmse_train = np.sqrt(mean_squared_error(y_pred_train_lin, y_train))
lin_rmse_train
26.527626721102603
How well does it do on the test set?
y_pred_test_lin = lin_reg.predict(X_test)
lin_rmse_test = np.sqrt(mean_squared_error(y_pred_test_lin, y_test))
lin_rmse_test
36.563500562427755
That’s quite impressive. On the test set, it performed better than the tree regressor. This shows that it’s realiable. Okay, but how badly is it overfitting?
lin_scores = cross_val_score(lin_reg, X_train, y_train,
scoring = "neg_mean_squared_error", cv=10
)
lin_rmse_scores = np.sqrt(-lin_scores)
display_scores(lin_rmse_scores)
scores: [ 30.05448244 33.26047826 39.80200849 42.4842238 21.47302677
31.36803597 18.7646719 63.04366609 44.5649017 30.41392853]
mean: 35.5229423942
standard deviation: 12.0935723986
Indeed, the Linear Model is not overfitting as bad as the Decision Tree model, and in fact, it also has a lower generalization error.
Random Forest Regressor
Random Forest model is prepared by performing decision tree regression on random subsets of the training data (X_train) and averaging out the predictions (essentially reducing variance). It is a type of ensemble learning algorithm.
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor()
First fit the regressor with X_train and y_train:
forest_reg.fit(X_train, y_train)
RandomForestRegressor(bootstrap=True, criterion='mse', max_depth=None,
max_features='auto', max_leaf_nodes=None,
min_impurity_split=1e-07, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
n_estimators=10, n_jobs=1, oob_score=False, random_state=None,
verbose=0, warm_start=False)
Then make a prediction of the target feature from X_train.
y_pred_train_forest = forest_reg.predict(X_train)
Finally, check the accuracy by calculating Root Mean Squared Error, that is, check how far off the predicted y is from the actual y_train.
# root mean square error
from sklearn.metrics import mean_squared_error
import numpy as np
forest_mse_train = mean_squared_error(y_pred_from_train, y_train)
forest_rmse_train = np.sqrt(forest_mse)
forest_rmse_train
17.194583863664128
Now, do this on the test dataset. Calculate rmse after predicting y using X_test. Recall that the regressor is trained on X_train and has not seen X_test. So, this is the real test of our model.
y_pred_test_forest = forest_reg.predict(X_test) #make the prediction
forest_mse_test = mean_squared_error(y_pred_from_test, y_test) #calculate rmse
forest_rmse_test = np.sqrt(forest_mse_test)
forest_rmse_test
35.263863915914143
The generalization error is only twice the training error. As expected, since the Random Forest model averages out it’s prediction on subsets of the training set, it is less prone to overfitting than the Decision Tree model which had a generalization error that was 14 times the training error.
Looking Ahead
Regularization
To abate overfitting of our models, constraints known as hyperparameters need to be introduced on the learning algorithms; thus, effectively simplifying our model. One such hyperparameter is regularization.
A hyperparameter can be too constraining, if it’s set to too large a value for instance. In that case, overfitting will certainly be avoided, but the model will be less likely to find a good solution. So, fine tuning the hyperparameters of the Decision Tree Algorithm, for example, is a natural next step.
Richer Features
Another action to improve our models is to, for instance, use the Linear Regressor but with a richer set of features. That is engineering features from the predictor features, including the text features we dropped for this post. This also involves getting rid of irrelevant features (maybe the anonymous series?)
Another Look at the Outliers?
Yet another option is to fix the quality of our data. That is, discarding the outliers or manually fixing them.
One concern here is that the outliers in the data, and the ones we detected above are not actually a result of a measurement or data collection error. Indeed, at the time of collection, any quora question has a certain value of number of questions, number of followers, etc. So, just discarding the anomalies as noise does not feel right. Need to think about this more.
Side Note
That the Linear Regression model performed as good (and even better) as the more complex decision tree model points the same direction as what Michele Banko and Eric Brill showed in their paper The Unreasonable Effectiveness of Data. They found out that fairly simple algorithms were able to perform identically well on a complex ml problem once both models were fed enough data. But don’t be mistaken, our dataset is not really large enough for us to actually reach the same conclusions as they did!
References
- Scikit-Learn Documentation.
- Hands-On Machine Learning with Scikit-Learn and TensorFlow by Aurélien Géron.